 Canal数据同步
Canal数据同步
Canal数据同步
一、介绍
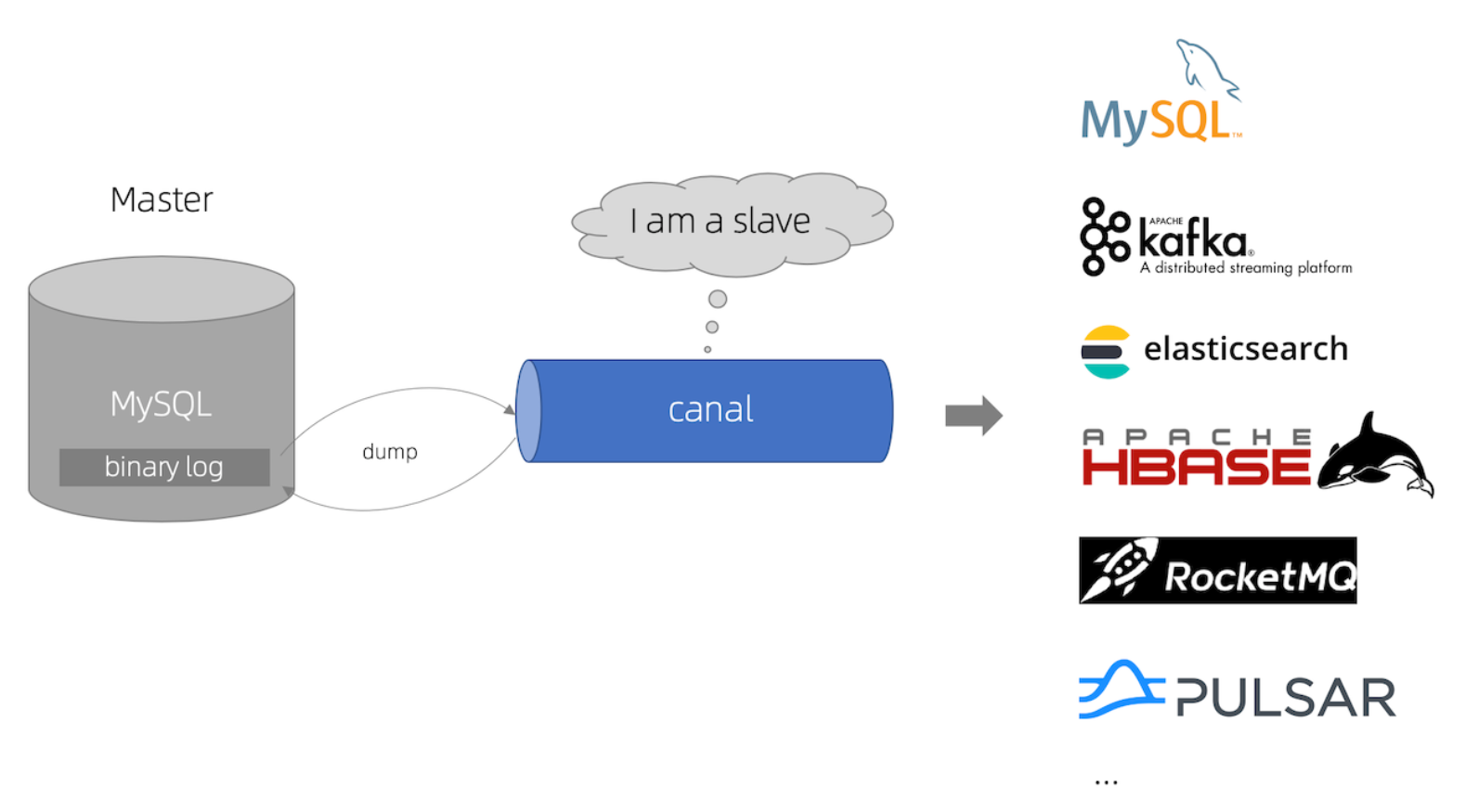
canal,译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费。
我们常常能遇到异构数据的同步问题,最典型的就是缓存一致性问题。之前我们需要在更新数据库后执行删除缓存操作,而这部分代码往往是高度耦合的。
canal是阿里巴巴开源的MySQL binlog 增量订阅&消费组件。它的原理是伪装成MySQL的从库来监听主库的binlog。因此,我们可以使用canal+MQ的方式把更新数据库和删除缓存进行解耦,同时还可以使用这种方式进行MySQL主从复制以及ES和MySQL的数据同步。
1、工作原理
MySQL主备复制原理
- MySQL master 将数据变更写入二进制日志( binary log, 其中记录叫做二进制日志事件binary log events,可以通过 show binlog events 进行查看)
- MySQL slave 将 master 的 binary log events 拷贝到它的中继日志(relay log)
- MySQL slave 重放 relay log 中事件,将数据变更反映它自己的数据
canal 工作原理
- canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送dump 协议
- MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
- canal 解析 binary log 对象(原始为 byte 流)
2、canal能做什么
以下参考canal官网。与其问canal能做什么,不如说数据同步有什么作用。
但是canal的数据同步不是全量的,而是增量,基于binary log增量订阅和消费。
canal可以做:
- 数据库镜像
- 数据库实时备份
- 索引构建和实时维护
- 业务cache(缓存)刷新
- 带业务逻辑的增量数据处理
二、环境搭建
1、MySQL
canal的原理是基于mysql binlog技术,所以这里一定需要开启mysql的binlog写入功能。
1)检查binlog写入功能是否开启
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | OFF |
+---------------+-------+
1 row in set (0.00 sec)
2)如果log_bin为OFF,则表示未开启,开启binlog写入功能
- 修改 mysql 的配置文件 my.cnf
vi /etc/my.cnf
追加内容:
log-bin=mysql-bin #binlog文件名
binlog_format=ROW #选择row模式
server_id=1 #mysql实例id,不能和canal的slave Id重复
- 重启 mysql
service mysql restart
- 登录 mysql 客户端,查看 log_bin 变量
mysql> show variables like 'log_bin';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| log_bin | ON|
+---------------+-------+
1 row in set (0.00 sec)
log_bin 为ON表示已开启。
2、Canal
我们使用docker来安装canal,首先拉取canal镜像,我们使用v1.1.5版本
docker pull canal/canal-server:v1.1.5
之后启动镜像,并将配置文件拷贝出来(先在root目录下创建canal文件夹)
docker run --name canal-server -id canal/canal-server:v1.1.5
# 复制配置文件
docker cp canal-server:/home/admin/canal-server/conf/ /root/canal
docker cp canal-server:/home/admin/canal-server/logs/ /root/canal
删除刚刚启动的容器,修改配置文件
修改Server配置文件root/canal/example/instance.properties,主要修改以下几个地方
## mysql serverId , v1.0.26+ will autoGen
canal.instance.mysql.slaveId= 20 #1、设置从库id,需要和刚刚mysql中设置的不同
# position info
canal.instance.master.address=mysql:3306 # 2、mysql地址,由于我的canal和mysql在一个网络下,因此直接使用mysql的容器名
#3、 username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
之后启动canal容器
docker run --name canal -p 11111:11111 \
-v /root/canal/conf/example/instance.properties:/home/admin/canal-server/conf/example/instance.properties \
-v /root/canal/conf/canal.properties:/home/admin/canal-server/conf/canal.properties \
-v /root/canal/logs/:/home/admin/canal-server/logs/ \
--network hm-net -d canal/canal-server:v1.1.5
验证是否启动成功
docker exec -it canal bash
cd canal-server/logs/example/
tail -100f example.log // 查看日志
3、TCP模式
从配置文件canal/conf/canal.properties中可以发现,canal默认模式为TCP模式,在TCP模式下可以使用客户端来接收
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = tcp
以Java客户端为例,首先需要引入依赖:
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
Client代码:
其中每次获取的entity的结构如图所示:
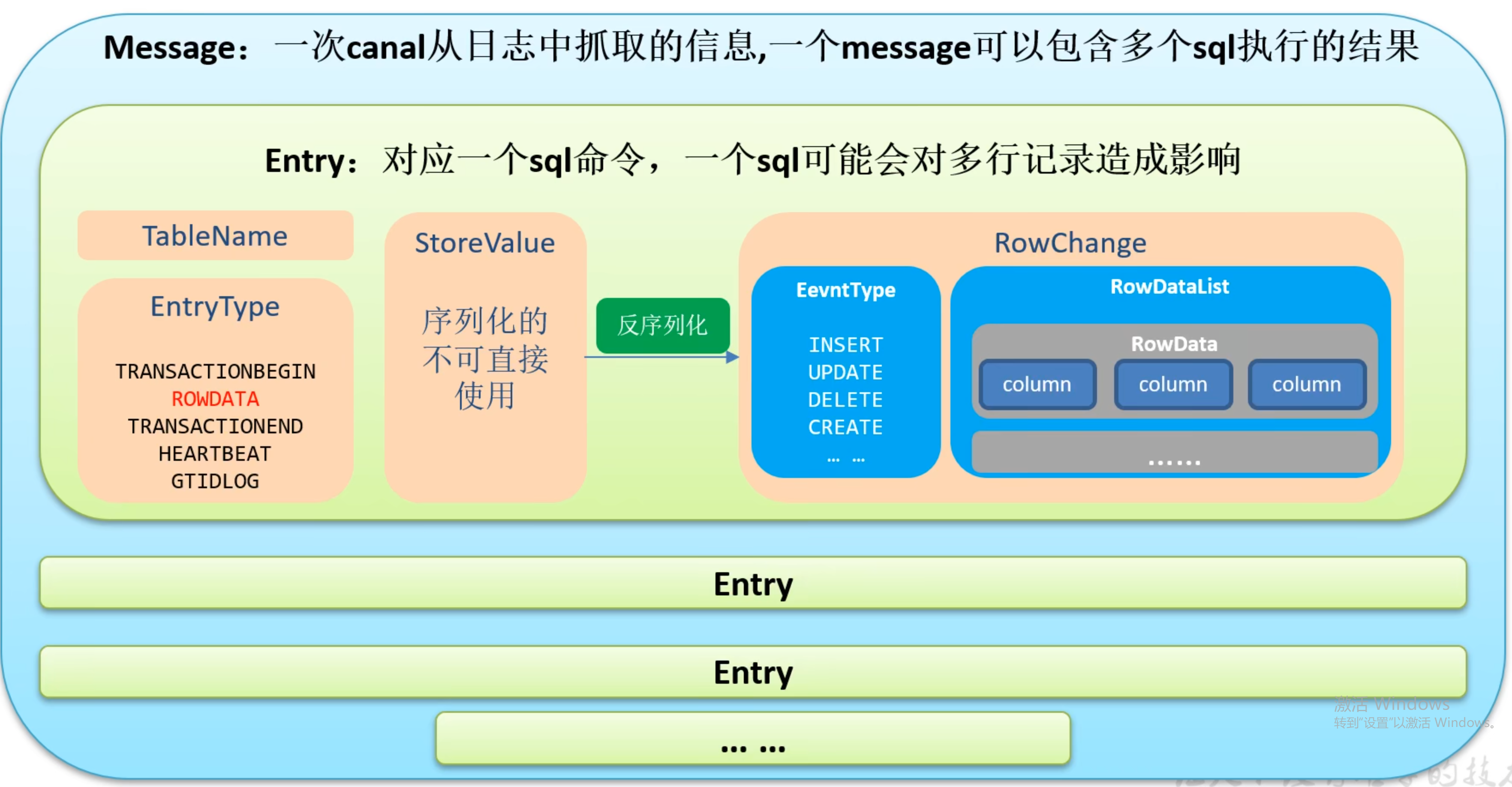
对数据的解析代码如下,还可以参考官网给出的一些开源解析工具
public class CanalClient {
//sql队列
private Queue<String> SQL_QUEUE = new ConcurrentLinkedQueue<>();
@Test
public void run() throws InterruptedException, InvalidProtocolBufferException {
//获取连接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress("192.168.175.129",
11111), "example", "", "");
//每次抓取的数据量,不足的话也不会阻塞,有多少读多少
int batchSize = 10;
while(true){
connector.connect();
connector.subscribe("hm-item.*"); // 订阅的数据库表
Message message = connector.get(batchSize); //获取数据
List<Entry> entries = message.getEntries(); //获取entity集合
if(entries.size() <= 0){
// System.out.println("当次抓取没有数据");
Thread.sleep(10000);
}else {
for (Entry entry : entries) {
//获取表名
String tableName = entry.getHeader().getTableName();
//获取类型
EntryType entryType = entry.getEntryType();
//获取序列化后的数据
ByteString storeValue = entry.getStoreValue();
//判断当前entryType是否为rawData
if(EntryType.ROWDATA.equals(entryType)){
RowChange rowChange = RowChange.parseFrom(storeValue); //反序列化数据
EventType eventType = rowChange.getEventType(); //获取当前事件的操作类型
//获取数据集(一个SQL可能改变多行数据)
List<RowData> rowDatasList = rowChange.getRowDatasList();
for (RowData rowData : rowDatasList) {
//获取改变前的数据以及改变后的数据
JSONObject beforeData = new JSONObject();
List<Column> beforeColumnsList = rowData.getBeforeColumnsList();
for (Column column : beforeColumnsList) {
beforeData.put(column.getName(), column.getValue());
}
JSONObject afterData = new JSONObject();
List<Column> afterColumnsList = rowData.getAfterColumnsList();
for (Column column : afterColumnsList) {
afterData.put(column.getName(), column.getValue());
}
//打印数据
System.out.println("===============================");
System.out.println("table:" + tableName+",eventType:"+eventType);
System.out.println("beforeData:"+beforeData);
System.out.println("afterData:"+afterData);
System.out.println("================================");
}
}
}
}
}
}
}
获取到数据后就可以进行下一步同步操作。
4、RabbitMQ模式
canal 作为 MySQL binlog 增量获取和解析工具,可将变更记录投递到 MQ 系统中,比如 Kafka/RocketMQ,可以借助于 MQ 的多语言能力。
1)修改配置文件canal/conf/canal.properties
# tcp, kafka, rocketMQ, rabbitMQ
canal.serverMode = rabbitMQ //1、模式修改为rabbitMQ
// 2、修改rabbitmq配置信息
##################################################
######### RabbitMQ #############
##################################################
rabbitmq.host = 192.168.175.129
rabbitmq.virtual.host = /hmall
rabbitmq.exchange = canal.direct
rabbitmq.username = hmall
rabbitmq.password = 123
rabbitmq.deliveryMode =
2)修改配置文件canal/conf/example/instance.properties
# table regex
canal.instance.filter.regex=hm-item\\..* //1、修改过滤规则,只监听hm-item数据库
# mq config
canal.mq.topic=example //2、设置mq的routing-key,必须和mq中设置的相同
在mq中创建对应的交换机和队列,重新启动canal并测试发现mq成功收到更新信息,后续可以使用mq消费者进行同步操作。
参考:
[1] https://github.com/alibaba/canal
[2] https://blog.csdn.net/weixin_42194695/article/details/125935200?utm_source=miniapp_weixin
[3] https://blog.csdn.net/weixin_42763696/article/details/132188296