 竞价排名
竞价排名
竞价排名
一、使用ElasticSearch
搜索业务并发压力可能会比较高,目前与商品服务在一起,不方便后期优化,为此我们将搜索业务单独拆分出来,创建一个新的微服务,并且使用elasticSearch作为搜索引擎。
1、创建索引库
由于要实现对商品搜索,所以我们需要将商品添加到Elasticsearch中,不过需要根据搜索业务的需求来设定索引库结构,而不是一股脑的把MySQL数据写入Elasticsearch.
搜索页面的效果如图所示:
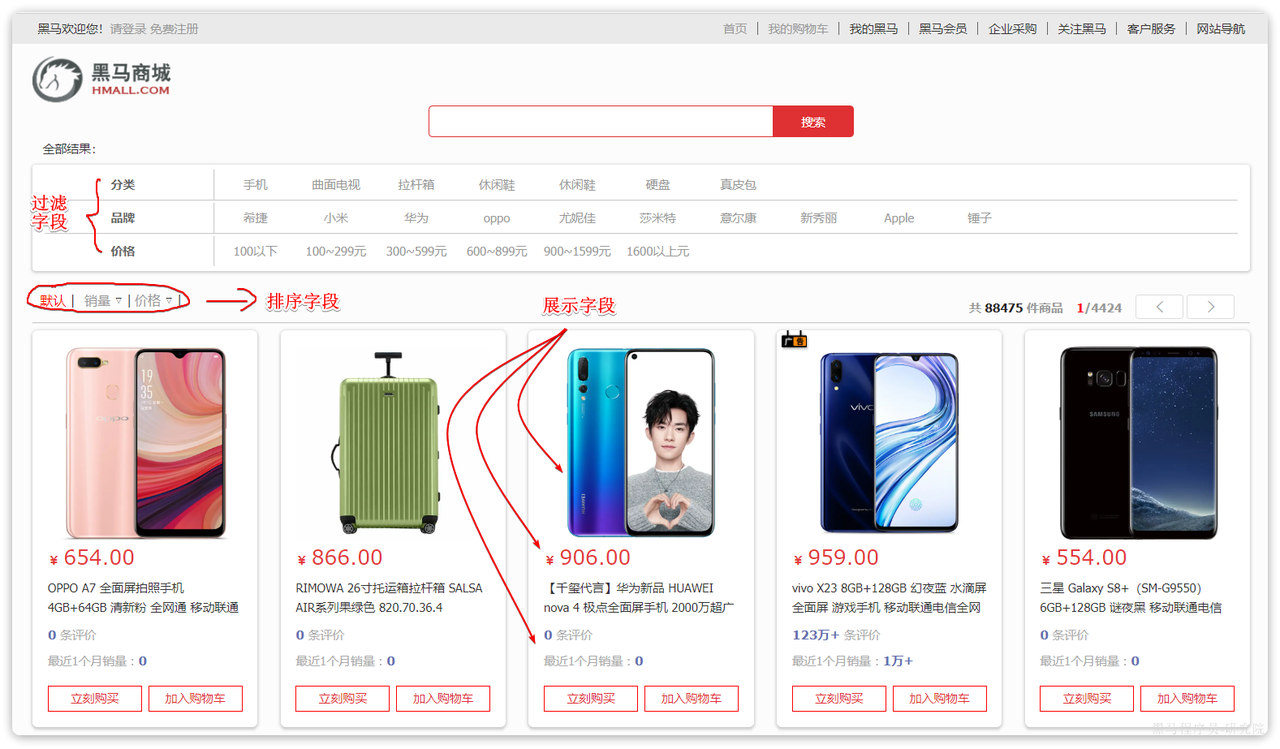
实现搜索功能需要的字段包括三大部分:
- 搜索过滤字段
- 分类
- 品牌
- 价格
- 排序字段
- 默认:按照更新时间降序排序
- 销量
- 价格
- 展示字段
- 商品id:用于点击后跳转
- 图片地址
- 是否是广告推广商品
- 名称
- 价格
- 评价数量
- 销量
对应的商品表结构如下,索引库无关字段已经划掉:
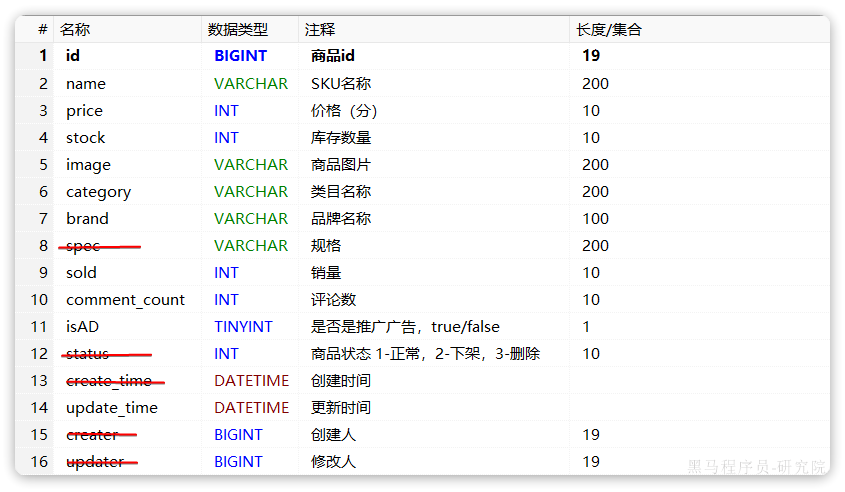
结合数据库表结构,以上字段对应的mapping映射属性如下:
| 字段名 | 字段类型 | 类型说明 | 是否****参与搜索 | 是否****参与分词 | 分词器 |
|---|---|---|---|---|---|
| id | long | 长整数 | —— | ||
| name | text | 字符串,参与分词搜索 | IK | ||
| price | integer | 以分为单位,所以是整数 | —— | ||
| stock | integer | 字符串,但需要分词 | —— | ||
| image | keyword | 字符串,但是不分词 | —— | ||
| category | keyword | 字符串,但是不分词 | —— | ||
| brand | keyword | 字符串,但是不分词 | —— | ||
| sold | integer | 销量,整数 | —— | ||
| commentCount | integer | 评价,整数 | —— | ||
| isAD | boolean | 布尔类型 | —— | ||
| updateTime | Date | 更新时间 | —— |
因此,最终我们的索引库文档结构应该是这样:
PUT /items
{
"mappings": {
"properties": {
"id": {
"type": "keyword"
},
"name":{
"type": "text",
"analyzer": "ik_max_word"
},
"price":{
"type": "integer"
},
"stock":{
"type": "integer"
},
"image":{
"type": "keyword",
"index": false
},
"category":{
"type": "keyword"
},
"brand":{
"type": "keyword"
},
"sold":{
"type": "integer"
},
"commentCount":{
"type": "integer",
"index": false
},
"isAD":{
"type": "boolean"
},
"updateTime":{
"type": "date"
}
}
}
}
代码分为三步:
- 1)创建Request对象。
- 因为是创建索引库的操作,因此Request是
CreateIndexRequest。
- 因为是创建索引库的操作,因此Request是
- 2)添加请求参数
- 其实就是Json格式的Mapping映射参数。因为json字符串很长,这里是定义了静态字符串常量
MAPPING_TEMPLATE,让代码看起来更加优雅。
- 其实就是Json格式的Mapping映射参数。因为json字符串很长,这里是定义了静态字符串常量
- 3)发送请求
client.``indices``()方法的返回值是IndicesClient类型,封装了所有与索引库操作有关的方法。例如创建索引、删除索引、判断索引是否存在等
在item-service中的IndexTest测试类中,具体代码如下:
@Test
void testCreateIndex() throws IOException {
// 1.创建Request对象
CreateIndexRequest request = new CreateIndexRequest("items");
// 2.准备请求参数
request.source(MAPPING_TEMPLATE, XContentType.JSON);
// 3.发送请求
client.indices().create(request, RequestOptions.DEFAULT);
}
static final String MAPPING_TEMPLATE = "{\n" +
" \"mappings\": {\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" },\n" +
" \"price\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"stock\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"image\":{\n" +
" \"type\": \"keyword\",\n" +
" \"index\": false\n" +
" },\n" +
" \"category\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"brand\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"sold\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"commentCount\":{\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"isAD\":{\n" +
" \"type\": \"boolean\"\n" +
" },\n" +
" \"updateTime\":{\n" +
" \"type\": \"date\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
2、新增文档
索引库结构与数据库结构还存在一些差异,因此我们要定义一个索引库结构对应的实体。
在hm-service模块的com.hmall.item.domain.dto包中定义一个新的DTO:
package com.hmall.item.domain.po;
import io.swagger.annotations.ApiModel;
import io.swagger.annotations.ApiModelProperty;
import lombok.Data;
import java.time.LocalDateTime;
@Data
@ApiModel(description = "索引库实体")
public class ItemDoc{
@ApiModelProperty("商品id")
private String id;
@ApiModelProperty("商品名称")
private String name;
@ApiModelProperty("价格(分)")
private Integer price;
@ApiModelProperty("商品图片")
private String image;
@ApiModelProperty("类目名称")
private String category;
@ApiModelProperty("品牌名称")
private String brand;
@ApiModelProperty("销量")
private Integer sold;
@ApiModelProperty("评论数")
private Integer commentCount;
@ApiModelProperty("是否是推广广告,true/false")
private Boolean isAD;
@ApiModelProperty("更新时间")
private LocalDateTime updateTime;
}
新增文档的请求语法与索引库操作的API非常类似,同样是三步走:
- 1)创建Request对象,这里是
IndexRequest,因为添加文档就是创建倒排索引的过程 - 2)准备请求参数,本例中就是Json文档
- 3)发送请求
变化的地方在于,这里直接使用client.xxx()的API,不再需要client.indices()了。
void testBulkDoc() throws IOException {
int pageNo = 1, pageSize = 500;
while (true){
//1、准备文档数据,查询数据库
Page<Item> page = itemService.lambdaQuery()
.eq(Item::getStatus, 1)
.page(Page.of(pageNo, pageSize));
List<Item> records = page.getRecords();
if (records == null || records.isEmpty()){
return;
}
//2、准备request
BulkRequest request = new BulkRequest();
//3、准备请求参数
for(Item record : records){
request.add(new IndexRequest("items")
.id(record.getId().toString())
.source(JSONUtil.toJsonStr(BeanUtil.copyProperties(record, ItemDoc.class)), XContentType.JSON));
}
//4、发送数据
client.bulk(request, RequestOptions.DEFAULT);
//5、翻页
pageNo++;
}
}
3、数据同步
采用异步双写方式进行数据ElasticSearch与MySQL的数据同步,在Mysql上进行数据增删改操作时,通过RabbitMQ异步将数据写入到ElasticSearch中。
新增 :
当新增商品时,ItemController将商品数据写入MySQL,同时通过MQ将消息发给搜索业务,将数据添加到ElasticSearch中:
@ApiOperation("新增商品")
@PostMapping
public void saveItem(@RequestBody ItemDTO itemDto) {
// 新增
Item item = BeanUtils.copyBean(itemDto, Item.class);
itemService.save(item);
//通过mq发送异步请求更新es
itemDto.setId(item.getId());
rabbitTemplate.convertAndSend("search.direct", "item.index", itemDto);
}
在搜索业务中监听mq消息:
private final ElasticSearch elasticSearch;
@RabbitListener(bindings = @QueueBinding(
value = @Queue(name = "search.item.index.queue", durable = "true"),
exchange = @Exchange(name = "search.direct"),
key = "item.index"
))
public void listenUpdate(ItemDTO item){
log.info("New item:{}", item);
elasticSearch.add(item);
}
最后处理消息,将item添加到es:
/**
* 更新es,新增
* @param item
*/
public void add(ItemDTO item) {
//1、转为文档数据类型
ItemDoc itemDoc = BeanUtils.copyProperties(item, ItemDoc.class);
//2、准备request
IndexRequest request = new IndexRequest("items").id(itemDoc.getId());
//3、准备json文档
request.source(JSONUtil.toJsonStr(itemDoc), XContentType.JSON);
//4、发送请求
try {
client.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
删除和修改的逻辑也类似...
4、条件搜索
原有的搜索业务是在MySQL中进行搜索,现在我们使用了ES,需要将原有的搜索修改为从ES中进行,分为以下三步:
- 构造request请求
- 发送请求
- 解析请求并返回给前端
1)根据前端提交的参数构造request请求
/**
* 获取搜索请求
* @param query
* @return
*/
public SearchRequest getSearchRequest(ItemPageQuery query) {
//1、获取request对象
SearchRequest request = new SearchRequest("items");
//2、配置request参数
BoolQueryBuilder bool = QueryBuilders.boolQuery();
//2.1 关键词搜索
if(query.getKey() != null && query.getKey() != ""){
bool.must(QueryBuilders.matchQuery("name", query.getKey()));
}else {
bool.must(QueryBuilders.matchAllQuery());
}
//2.2 品牌名过滤
if(query.getBrand()!= null && query.getBrand() != ""){
bool.filter(QueryBuilders.termQuery("brand", query.getBrand()));
}
//2.3 种类过滤
if(query.getCategory()!= null && query.getCategory() != ""){
bool.filter(QueryBuilders.termQuery("category", query.getCategory()));
}
// 2.4 价格过滤
RangeQueryBuilder rangedQuery = QueryBuilders.rangeQuery("price");
if(query.getMaxPrice() != null && query.getMaxPrice() != 0){
rangedQuery.lte(query.getMaxPrice());
}
if(query.getMinPrice() != null && query.getMinPrice() != 0){
rangedQuery.gte(query.getMinPrice());
}
bool.filter(rangedQuery);
//3、排序和分页
request.source().query(bool);
request.source().sort("updateTime", SortOrder.DESC);
request.source().from((query.getPageNo()-1) * query.getPageSize()).size(query.getPageSize());
return request;
}
2)发送请求
public PageDTO<ItemDTO> search(ItemPageQuery query){
SearchRequest request = getSearchRequest(query);
//4、发送请求
SearchResponse response = null;
try {
response = client.search(request, RequestOptions.DEFAULT);
//5、解析请求
PageDTO<ItemDTO> pageDTO = handleResponse(response);
return pageDTO;
} catch (IOException e) {
throw new RuntimeException(e);
}
}
3)解析请求并包装成PageDTO返回
private PageDTO<ItemDTO> handleResponse(SearchResponse response) {
PageDTO<ItemDTO> pageDTO = new PageDTO<>();
SearchHits searchHits = response.getHits();
// 1.获取总条数
long total = searchHits.getTotalHits().value;
pageDTO.setTotal(total);
// 2.遍历结果数组
List<ItemDTO> list = new ArrayList<>();
SearchHit[] hits = searchHits.getHits();
if(hits == null || hits.length == 0){
return pageDTO;
}
for (SearchHit hit : hits) {
// 3.得到_source,也就是原始json文档
String source = hit.getSourceAsString();
// 4.反序列化
ItemDTO item = JSONUtil.toBean(source, ItemDTO.class);
list.add(item);
}
pageDTO.setList(list);
Long pages = total / list.size();
pageDTO.setPages(pages);
return pageDTO;
}
二、竞价排名
前面我们展示的顺序都是按照时间进行展示,但是我们想要将投放广告的商品进行优先展示。elasticsearch的默认排序规则是按照相关性打分排序,而这个打分是可以通过API来控制的。我们可以通过改变算分函数,对投放广告的商品打高分从而实现竞价排名,竞价排名和普通搜索的区别在于构造request请求不同,代码如下:
/**
* 广告优先
* @param query
* @return
*/
public SearchRequest getSearchRequestAd(ItemPageQuery query) {
//1、获取request对象
SearchRequest request = new SearchRequest("items");
//2、配置request参数
BoolQueryBuilder bool = QueryBuilders.boolQuery();
//2.1 关键词搜索
if(query.getKey() != null && query.getKey() != ""){
bool.must(QueryBuilders.matchQuery("name", query.getKey()));
}else {
bool.must(QueryBuilders.matchAllQuery());
}
//2.2 品牌名过滤
if(query.getBrand()!= null && query.getBrand() != ""){
bool.filter(QueryBuilders.termQuery("brand", query.getBrand()));
}
//2.3 种类过滤
if(query.getCategory()!= null && query.getCategory() != ""){
bool.filter(QueryBuilders.termQuery("category", query.getCategory()));
}
// 2.4 价格过滤
RangeQueryBuilder rangedQuery = QueryBuilders.rangeQuery("price");
if(query.getMaxPrice() != null && query.getMaxPrice() != 0){
rangedQuery.lte(query.getMaxPrice());
}
if(query.getMinPrice() != null && query.getMinPrice() != 0){
rangedQuery.gte(query.getMinPrice());
}
bool.filter(rangedQuery);
FunctionScoreQueryBuilder scoreQueryBuilder = QueryBuilders.functionScoreQuery(
// 原始查询,相关性算分
bool,
// function score的数组
new FunctionScoreQueryBuilder.FilterFunctionBuilder[]{
// 其中的一个function score元素
new FunctionScoreQueryBuilder.FilterFunctionBuilder(
// 过滤条件
QueryBuilders.termQuery("isAD", true),
// 算分函数
ScoreFunctionBuilders.weightFactorFunction(10))
});
//3、排序和分页
request.source().query(scoreQueryBuilder);
request.source().sort("_score", SortOrder.DESC);
request.source().sort("updateTime", SortOrder.DESC);
request.source().from((query.getPageNo()-1) * query.getPageSize()).size(query.getPageSize());
return request;
}